随着大数据技术的快速发展,Apache Spark 已成为构建高效、可扩展大数据服务的核心产品之一。在面试大数据相关岗位时,深入理解 Spark 的原理、应用及优化策略至关重要。本文将梳理 Spark 的核心面试题,并探讨其在构建大数据服务中的应用,为求职者提供全面的准备指南。
一、Spark 核心概念与架构面试题
1. Spark 与 Hadoop MapReduce 的主要区别是什么?
Spark 基于内存计算,通过弹性分布式数据集(RDD)实现高效迭代处理,比基于磁盘的 MapReduce 快数十倍。Spark 提供了统一的批处理、流处理、机器学习和图计算框架,而 MapReduce 仅专注于批处理。
2. 解释 Spark 的架构和核心组件。
Spark 采用主从架构,包括:
- Driver Program:运行用户主程序,创建 SparkContext,负责作业调度与执行。
- Cluster Manager:管理集群资源(如 YARN、Mesos 或 Standalone 模式)。
- Executor:在工作节点上运行任务,负责数据计算与存储。
- RDD(弹性分布式数据集):Spark 的基本数据结构,具有容错性和并行处理能力。
3. 什么是 RDD?它的特性有哪些?
RDD 是 Spark 中不可变、分区的数据集合,支持并行操作。特性包括:
- 容错性:通过血缘关系(Lineage)记录转换过程,丢失时可重新计算。
- 惰性求值:转换操作(如 map、filter)延迟执行,直到遇到行动操作(如 collect、save)才触发计算。
- 持久化:可缓存到内存或磁盘,加速重复计算。
二、Spark 性能优化与调优面试题
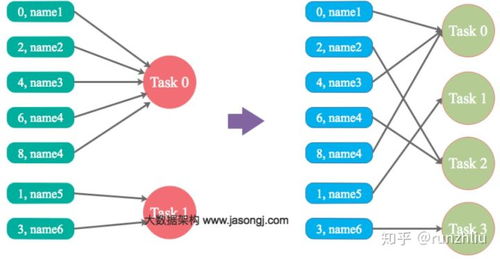
1. 如何避免 Spark 作业中的 Shuffle 操作过度?
Shuffle 是性能瓶颈,优化方法包括:
- 使用
reduceByKey替代groupByKey,在分区内预先聚合减少数据传输。
- 增加分区数或调整
spark.sql.shuffle.partitions参数。
- 使用广播变量(Broadcast Variables)减少小表关联时的 Shuffle。
2. 解释 Spark 的内存管理机制。
Spark 内存分为:
- Execution Memory:用于 Shuffle、排序等计算过程。
- Storage Memory:用于缓存 RDD 和数据。
两者可动态占用,通过 spark.memory.fraction 参数调整比例。合理配置可避免 OOM(内存溢出)错误。
- 如何调试 Spark 作业的慢任务?
- 使用 Spark UI 分析各阶段执行时间、数据倾斜情况。
- 检查数据分区是否均匀,可通过
repartition或coalesce调整。
- 监控 GC(垃圾回收)频率,优化 JVM 参数。
三、Spark 在大数据服务中的应用场景
- 实时数据处理:通过 Spark Streaming 或 Structured Streaming 构建低延迟流处理服务,如实时日志分析、金融风控。
- 数据仓库与 ETL:利用 Spark SQL 处理大规模结构化数据,替代传统 Hive 查询,提升数据清洗和转换效率。
- 机器学习平台:集成 MLlib 库,支持分布式模型训练与推荐系统构建。
四、实战准备建议
- 掌握编码能力:熟练使用 Scala、Python 或 Java 编写 Spark 作业,重点练习 DataFrame API 和 Spark SQL。
- 理解生态集成:熟悉 Spark 与 Hadoop、Kafka、HBase 等组件的协作方式。
- 模拟场景问题:准备如何设计一个高可用的 Spark 大数据服务,包括故障恢复、资源调度和监控告警策略。
Spark 作为大数据产品的核心,其面试不仅考察理论知识,更注重解决实际问题的能力。求职者应结合项目经验,深入理解 Spark 的优化技巧和服务化部署,从而在面试中展现全面的技术视野。